Programming with PTRACE, Part5 - 内存管理
这个part主要讲解Linux的内存管理机制,以及如何查看并限制子进程的内存使用。
内存的划分
(嘛。。。这一部分也算是现学现卖的,如果大家觉得有什么讲的不到位的请翻下方的拓展阅读部分)
大家都知道,32位系统最大可以寻址4GB的地址空间(不考虑物理地址扩展),那么这个“地址”究竟指的是哪儿的地址呢?你可以写一个小程序,malloc一点内存,然后把地址打印出来,重复几次,你会发现,分配的内存几乎都在同一个位置。这是因为,对于程序来说,这些地址都是虚拟地址,虚拟地址空间对于每个进程都是独立的,也就是说,对于不同的进程,同样虚拟地址上的数据是不同的。
当然,数据肯定是存放在内存条上的,我们把可以直接读写内存条的地址叫做物理地址。物理地址以一定的方式映射到虚拟地址上,所以当程序试图访问虚拟地址时,系统要以一定方式把虚拟地址变成物理地址,这项工作通常是由MMU(内存管理单元)来完成的。内存的映射不是大块大块的,而是一小片一小片分别映射的,所以在虚拟地址上连续的地址可能在物理地址上相差十万八千里,这些一小片一小片的内存被称为“页”。
页的存在给内存分配带来了极大的灵活性,页可以存储在内存里,也可以存储在交换分区里,可以将同一块物理内存映射到不同进程的虚拟空间里(动态库经常这么干),甚至可以映射到磁盘上的某个文件。光说可能有点抽象,于是给幅图(来自Wikipedia)
虚拟地址被分成多个段,数据有序存放于其中。这是32位Linux的新内存布局(Linux 2.6.7之后):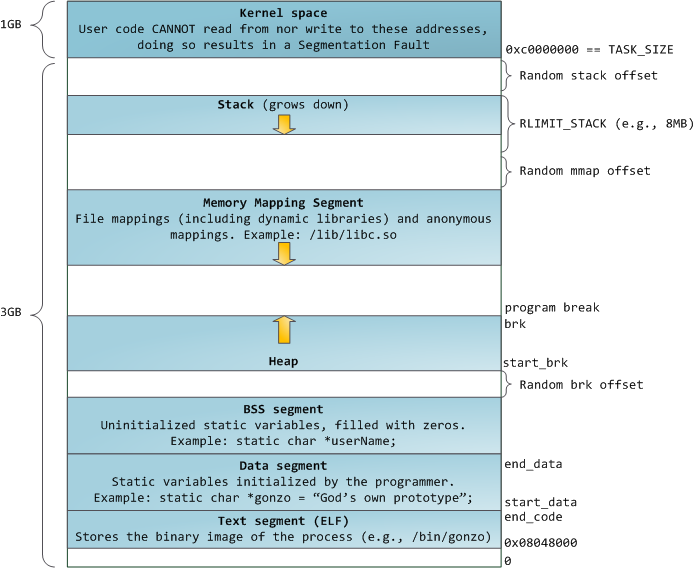
如果你研究过可执行文件的结构,你就会发现,虚拟地址的段就是按可执行文件的段来填充的。另外,由于代码段的起点地址是固定的(0x08048000),所以编译器就可以预先算出函数的地址了。顺带一提,因为动态库加载时的虚拟地址是不固定的,不能预先计算出函数地址,所以要在编译时使用-fPIC选项生成位置无关代码,否则每次被一个新进程使用时都要进行重定位(可以理解为重新计算函数地址),并生成该动态库的一个副本,这样压根没有起到节约内存的作用。
扯远了,回来。尽管每个进程的虚拟地址空间时互相独立的,但并不意味着进程想访问哪儿就能访问的,比如3GB以上的区域,那儿是内核的领地。即使是堆段,也只能访问已申请的内存部分,非法的内存访问将会引发段错误(Segmentation Fault)。回到malloc()函数上,malloc最终会调用brk或mmap系统调用,brk用于在堆中分配小块内存,mmap则用于在Memory Mapping Segment中分配大块内存。但是并不是每次malloc都会调用brk,这是因为分配的内存实在是太小了,而brk只能分配大一点的内存,所以C运行库(比如glibc)在收到一个malloc时会先用brk向系统“批发”一块大一点的内存,而收到后续分配请求时则把这块大内存“零售”给程序,直到售完再次brk。
如果有一个程序死循环单纯malloc内存,内存会不会被吃光呢?答案是不会(我不清楚是不是真的有如此单纯的系统真的会挂掉),因为系统发现,你只是分配了内存,却没有使用,于是它很机智地将那片内存设置为“可访问”,却没有把它映射到任何一个实际的内存页上!
你用了多少内存?
还记得之前的rusage结构么?其成员可在这里找到。事实上,这是一种非常简陋的内存使用信息获取方式,我们只关心其中的ru_maxrss一项,RSS即"Resident Set Size",表示该进程在物理内存中的占用大小,不包括交换分区中的内存大小,也不包含分配了却未使用而没有物理内存页的内存。为了获得更详细的内存信息,我们需要访问/proc目录。该目录下各文件的用途在man 5 proc里描述得很清楚,这里是网页版本。关于这个目录的作用,我就偷懒,将man手册中的描述翻译如下:
proc文件系统是一个伪文件系统,提供了访问内核数据结构的接口。它通常被挂载在/proc上并且大部分是只读的,除了少数文件被允许用来改变内核参数。
/proc下有N多文件夹,大部分是按进程的pid来命名的,我们关心的是这些文件夹中的status文件。来看一个例子:cat /proc/1/status|grep Vm
VmPeak: 173616 kB
VmSize: 107968 kB
VmLck: 0 kB
VmPin: 0 kB
VmHWM: 3816 kB
VmRSS: 3744 kB
VmData: 83744 kB
VmStk: 136 kB
VmExe: 1140 kB
VmLib: 2268 kB
VmPTE: 72 kB
VmSwap: 0 kB我们看到了两个令人感兴趣的东西:VmData和VmStk。分别代表了数据区和栈的大小,而且这两个数据是真正的可访问的虚拟内存大小,即不会像RSS那样,漏掉那些分配了而未访问的内存。当然,其他数据也都是很有趣的,有兴趣的人可以自己去翻man手册。这段代码计算给定进程的数据段和堆栈段内存使用总和。
1 | long getMemory(const pid_t pid){ |
限制内存
也许你们已经知道,有一个叫做setrlimit的函数可以用来限制资源使用,你们也许已经翻过了它的man手册,看到了RLIMIT_AS RLIMIT_DATA RLIMIT_RSS等一票似乎很有用的参数。现在,请你立刻忘掉他们!既然我们之前讲了/proc当然要用起来啦。我们不用setrlimit是因为,这种限制策略会导致malloc失败(确切的讲是brk和mmap失败),而大部分OIer都没有检查malloc返回值的的习惯,最终导致本应是MLE(Memory Limit Exceeded)的情况变成了由访问无效内存导致的RE(Runtime Error)。更糟糕的是,如果是系统栈增长被限制了,进程会被直接SIGSEGV,连errno都没有,这种情况下就更难分辨了。那么,有什么好的方法来限制内存呢?答案就是在每次分配内存的系统调用(不限于brk和mmap)时通过proc来检查内存使用,注意要在返回时检查哦。一旦超过,就由父进程直接杀死子进程,方法多种多样,你可以使用ptrace(PTRACE_KILL,pid,0,0),或是用Part3所讲的方法发送信号,或是直接用kill函数。这种方法看上去很不优雅,但确实很有效。至于那些对setrlimit耿耿于怀的同学,不要担心,下个part时间限制,将会大量用到。
拓展阅读&参考资料
- Linux内存管理详解
- Linux进程地址空间详解
- Linux虚拟地址空间布局
- OJ系统各状态含义(见Question #6;应该还有一个RF:Restricted Function)
- Anatomy of a Program in Memory
- man手册