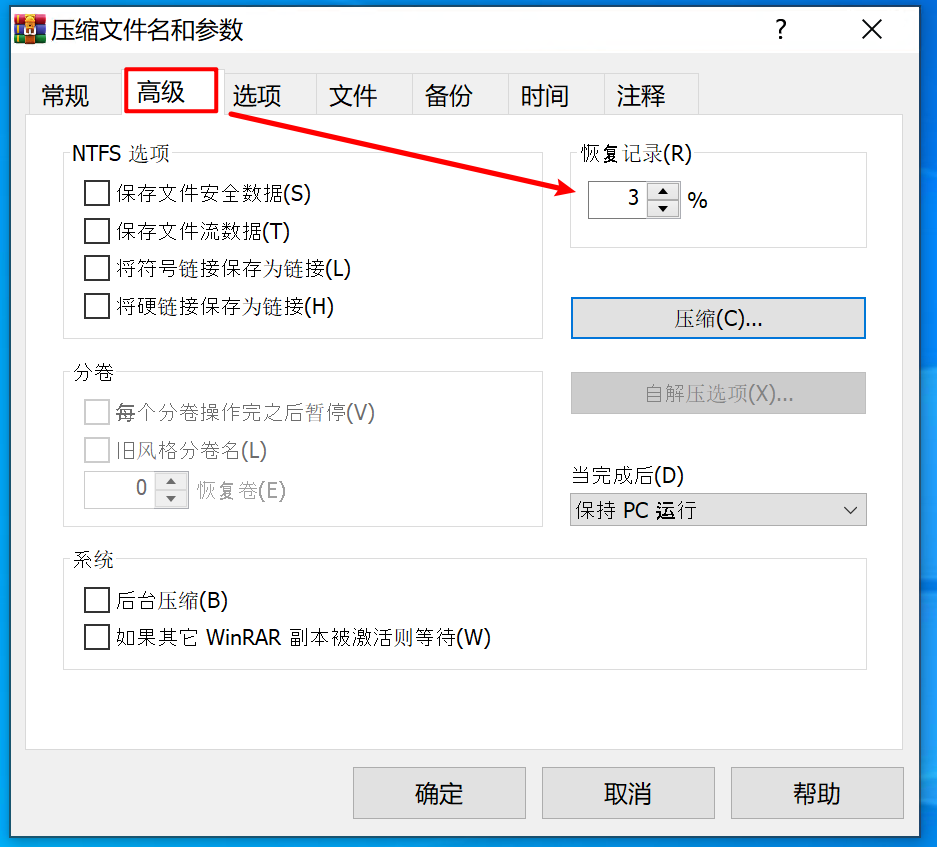
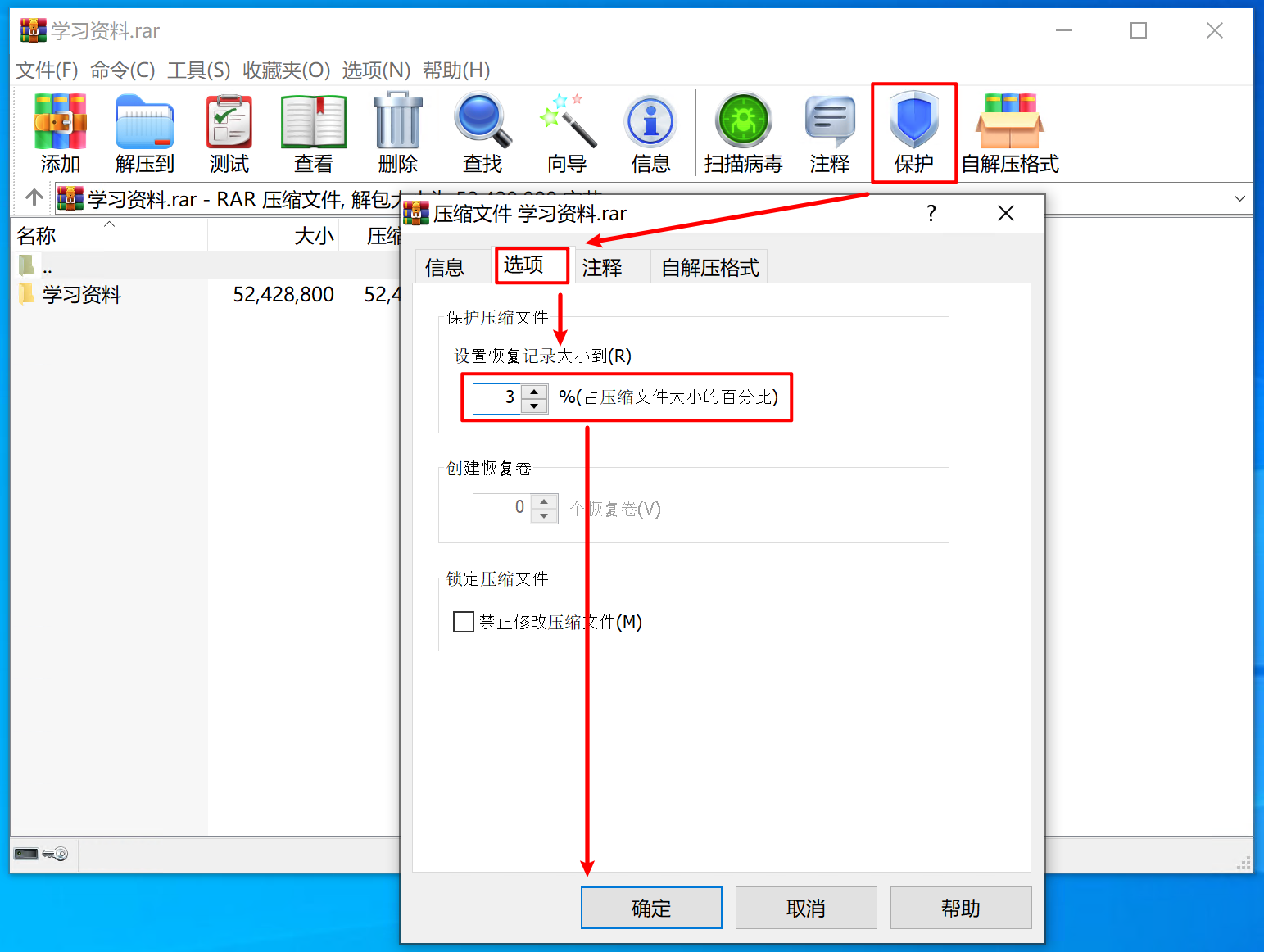
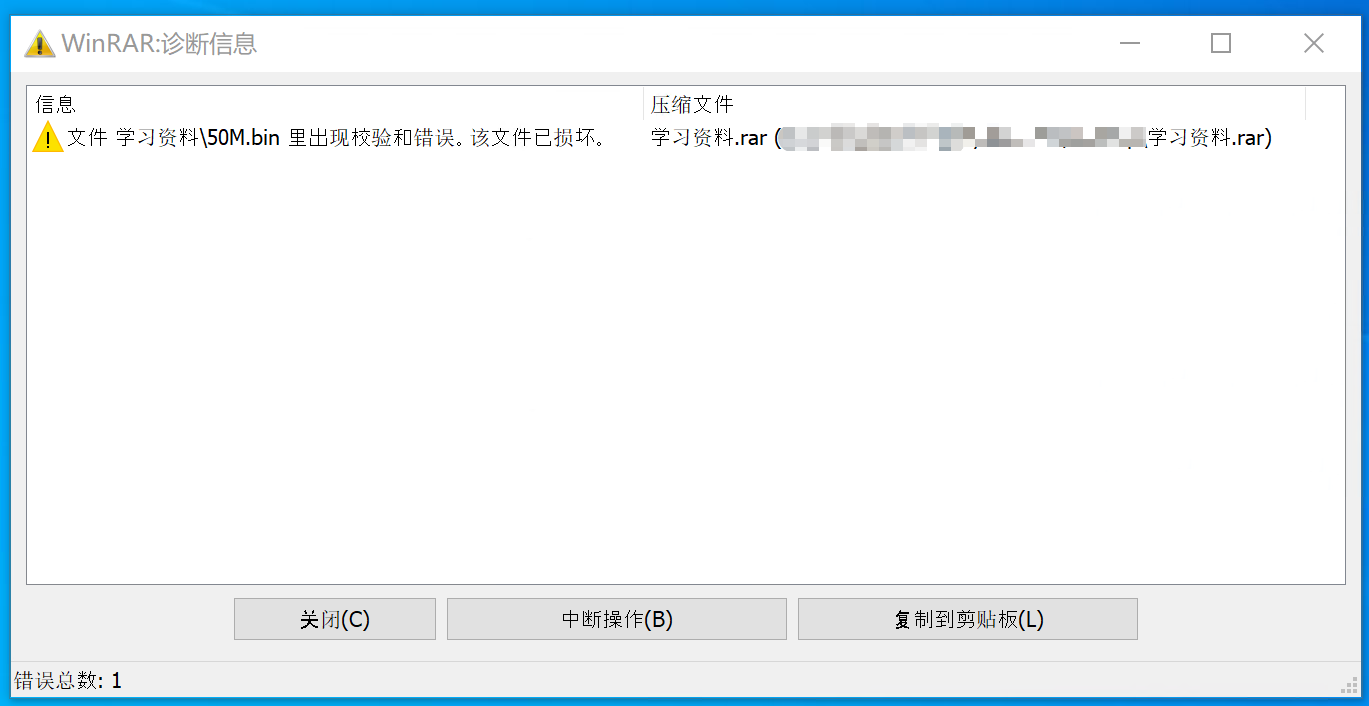
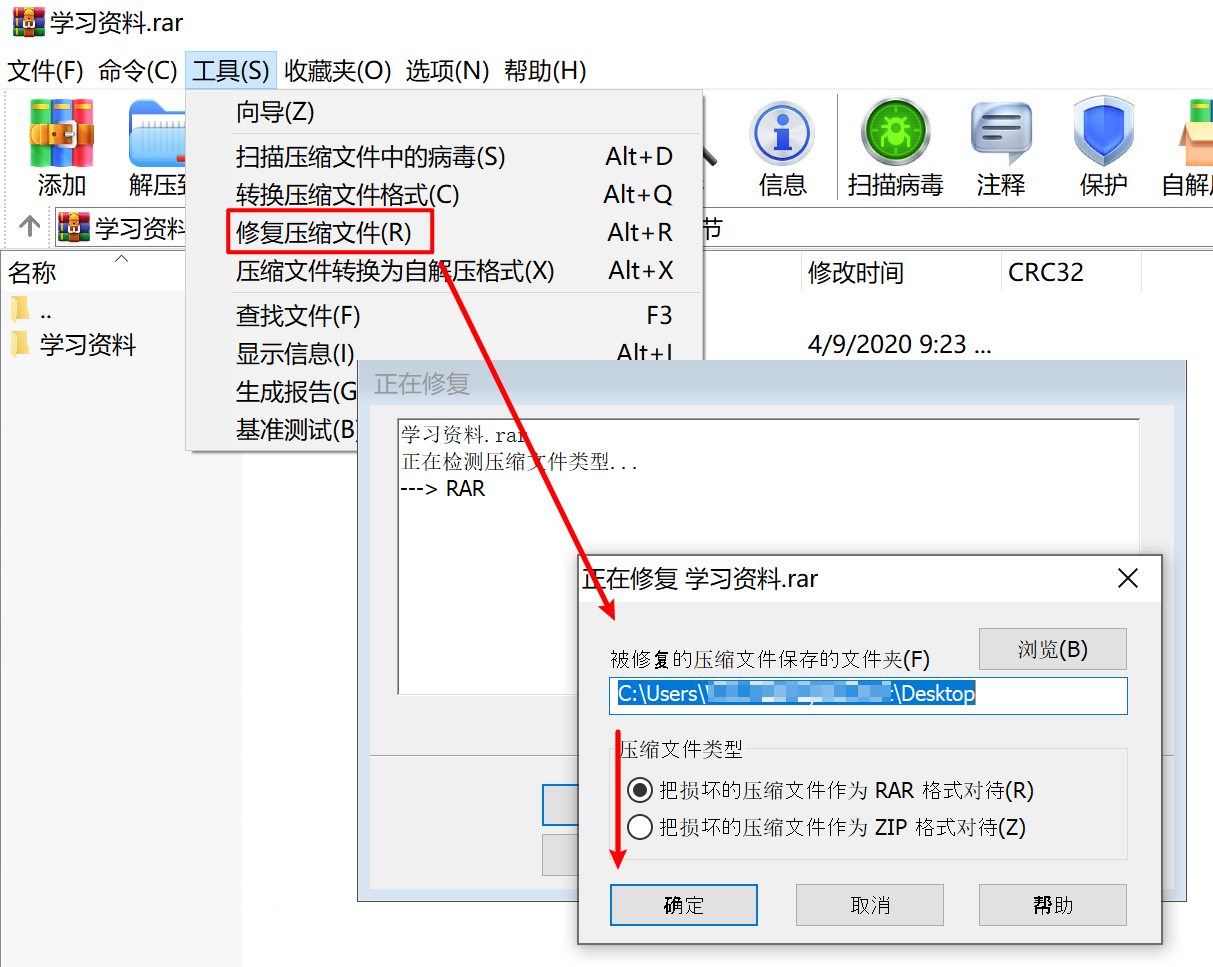
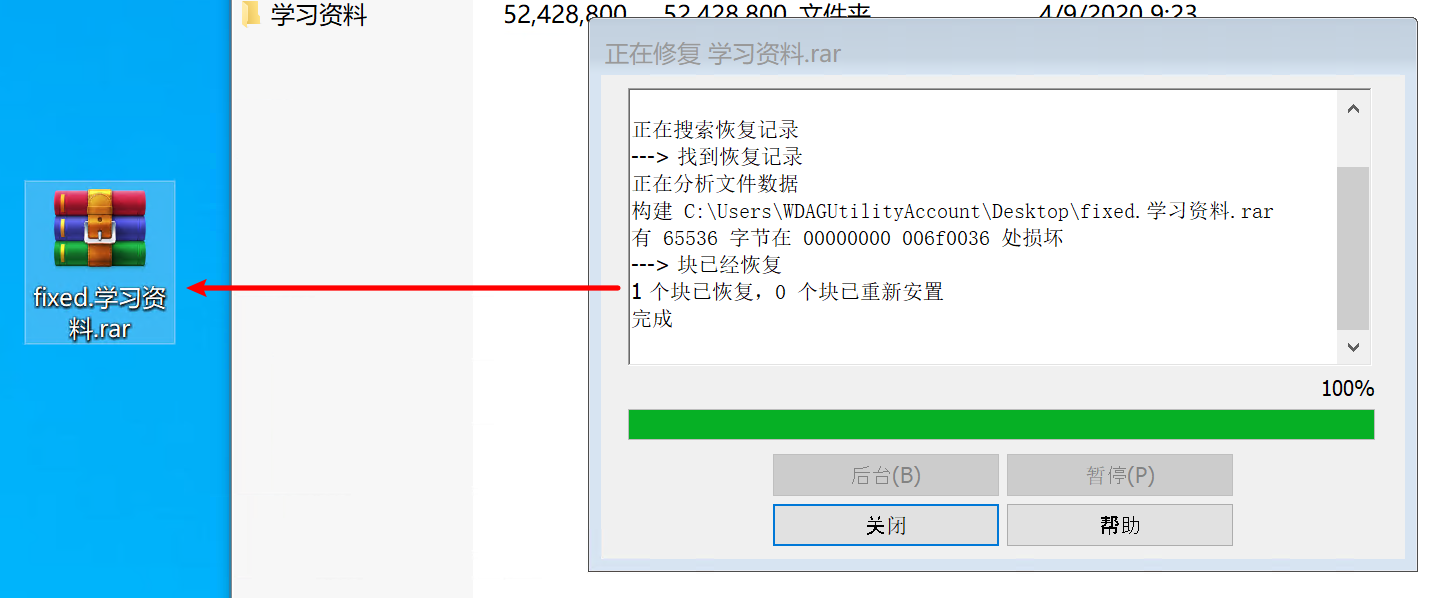
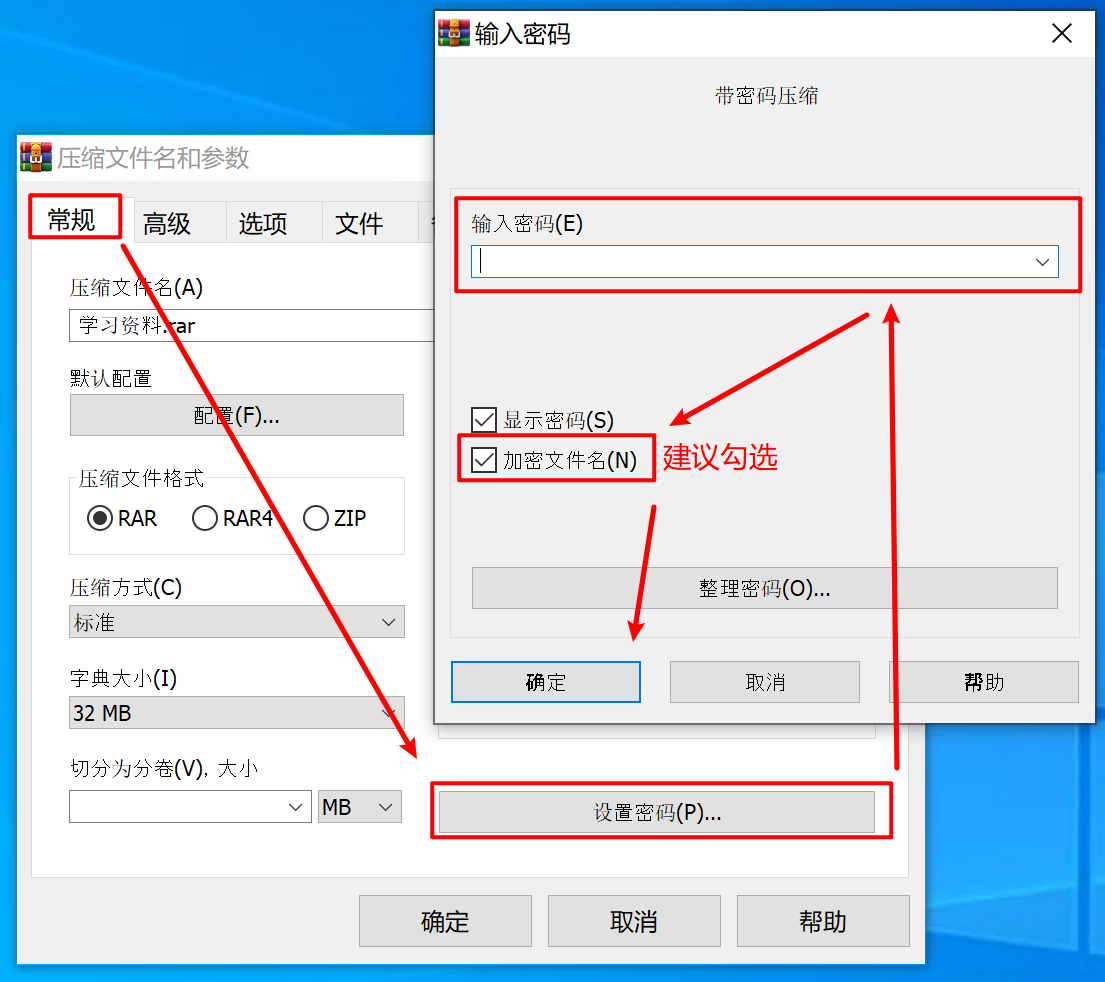
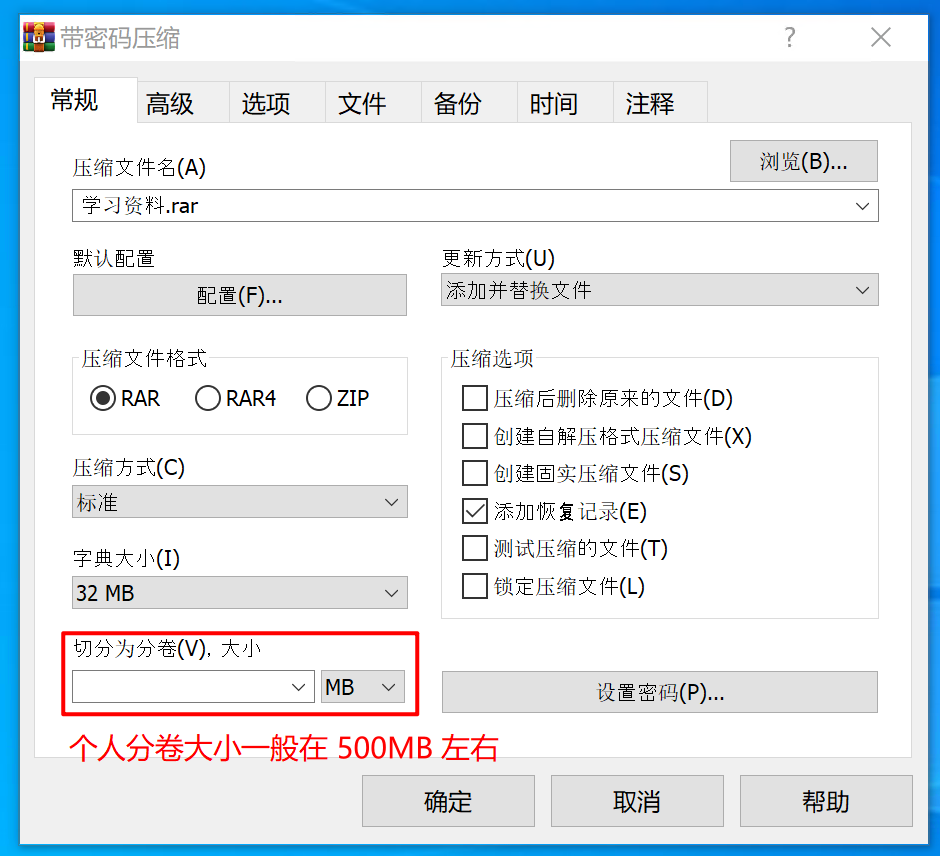
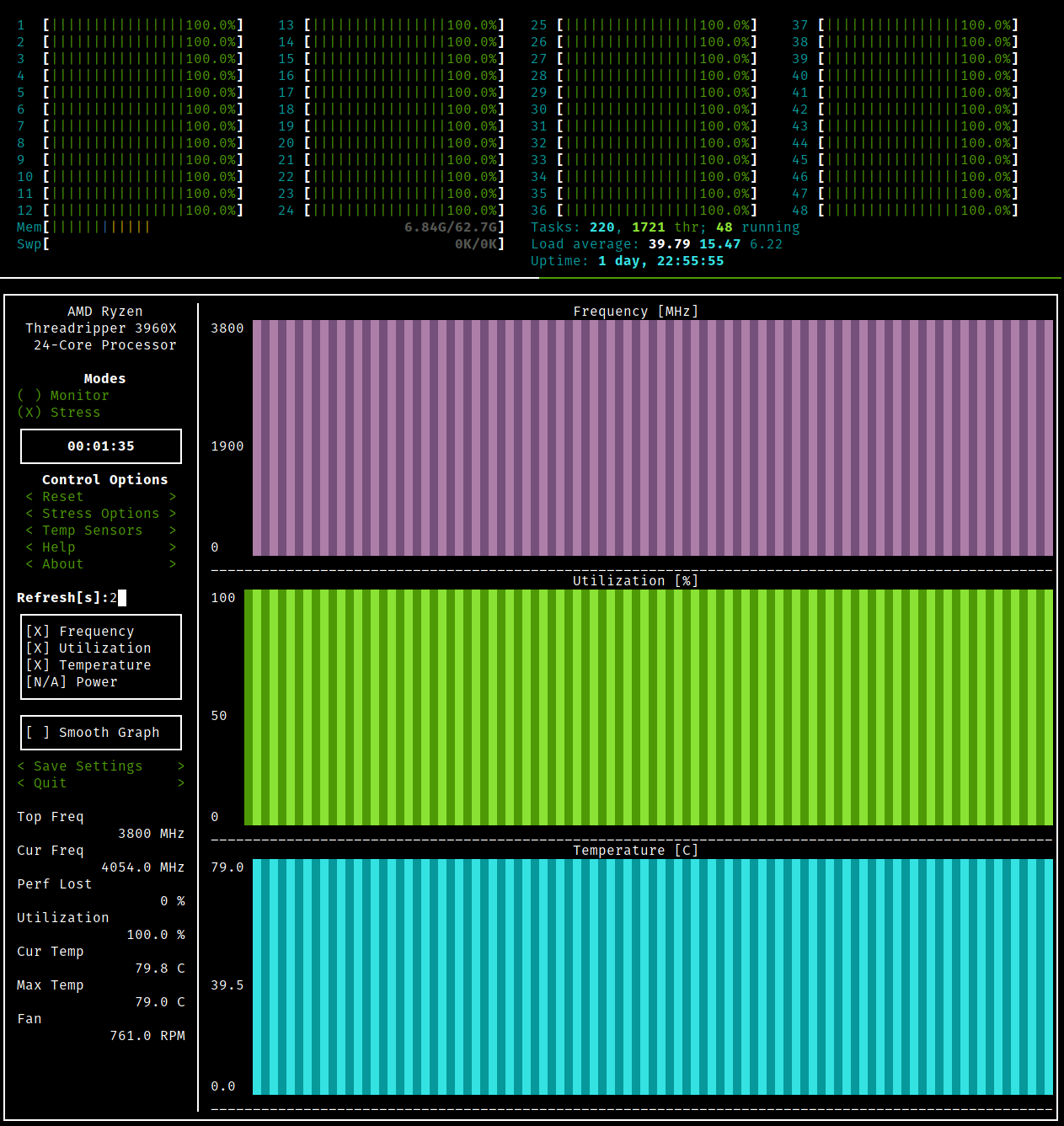
磁带机买来干什么?鉴于磁带的顺序读写以及需要手动换磁带(买带库的大佬请忽略)的特性,注定了它只适合于备份和归档用途。备份像是重疾保险,你希望永远也用不上;归档是你 6 岁时的玩具,舍不得丢但也不会再用。所以如果你说 NAS 空间不够,要用磁带来存你的电影,我觉得不太行。但如果你仓鼠症发作,打算收集世界上所有的电影,磁带大概可行。
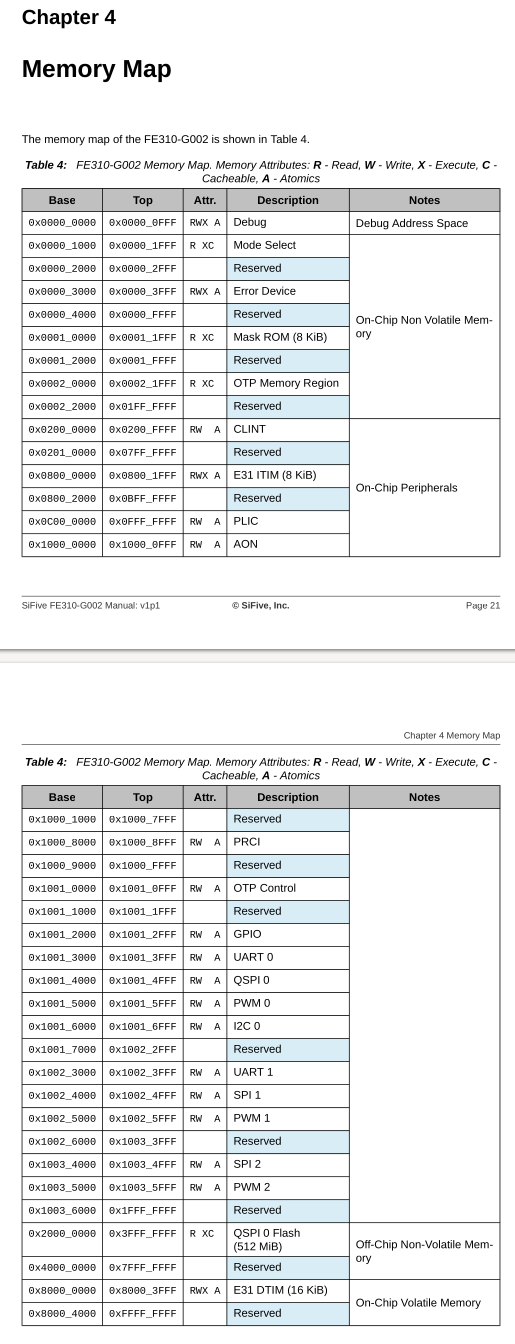
Allison Sheridan: So a Thunderbolt 4 device is a USB4 device...Brad Saunders: (nodding)Allison Sheridan: ...but a USB4 device is not necessarily a Thunderbolt 4 device?Brad Saunders: It can be ...Allison Sheridan: It can be but it isn't necessarily.Brad Saunders: It'll probably have... they may have made a choice to... maybe it's only 20 Gbps.Allison Sheridan: Right, but it's Thunderbolt 4 it's 40 [Gbps] per second, Okay.
]]>
<p><img src="/images/usb4-thunderbolt4-memo/01-summary-diagram.png" alt="Summary"></p>
<p>最近研究了一些关于 USB4 以及 Thunderbolt 4 的资料,在此做个备忘。目前只考虑 U
手动硬盘安装 WePEhttps://recursiveg.me/2021/06/manual-wepe-installation/2021-06-22T14:00:00.000Z2021-06-23T03:27:31.548Z最近尝试了一些 Windows 下的全盘备份/恢复方案,于是顺便折腾了一下各种 WinPE 系统。WinPE 简单来说就是一个 Windows 的 LiveCD,带有各种用于 Windows 的工具。网友们在微软的 WinPE 基础上加入各种驱动和方便使用的图形化操作界面,作为不同的 WinPE “发行版”发布,微PE(WePE) 是这些“发行版”之一。
WePE 自带的安装程序除了安装必要的启动项以外还会安装一些没啥用的选项。所以记录一下手动安装启动项的方法。环境为 Windows 10 64位 UEFI 启动。你需要先制作 WePE 的 ISO,然后把 ISO 里的WEPE目录复制到随便一个分区里,我假设是D:。用管理员身份执行以下命令:
]]>
<p>最近尝试了一些 Windows 下的全盘备份/恢复方案,于是顺便折腾了一下各种 <a href="https://docs.microsoft.com/en-us/windows-hardware/manufacture/desktop/winpe-intro" targe
Ciphersuite Memohttps://recursiveg.me/2021/02/ciphersuite-memo/2021-02-21T11:30:00.000Z2023-01-22T02:04:43.554ZI'm sorry if you landed in this keywords soup only to find it not helpful.
A related concept is mode of operation,which turns a block cipher to a stream cipher. CBC is a commonly used one. When it's used with AES, it's expressed as AES-CBC
Message authentication Used for data integrity. These algorithms are also called MAC(Message authentication code).
Authenticated Encryption (AE) Combines confidentiality and integrity. Wikipedia: Authenticated Encryption.
EtM (Encrypt-then-MAC): A secure way to combine encryption algorithms with MAC algorithms.
GCM (Galois/Counter Mode): A mode of operation, when paired with a block cipher, offers AE (actually AEAD) in one step.
Some commonly used AE methods:
AES-CBC with an HMAC e.g.AES128-CBC-HMAC-SHA256.
ChaCha20 with Poly1305.
AES-GCM
Authenticated Encryption with Associated Data (AEAD) Similar to AE, but allows extra unencrypted data (associated data) to be authenticated. Roughly speaking:
A common use case for AEAD is when encrypting a network packet, you want the packet header to stay unencrypted (for network routing purposes) but still authenticated.
Note about DH and curves of EC-based algorithms DH-based algorithms may have a “Group” option, which specifies a prime field or an elliptic curve. If a prime field is used, such as modp2048, it's normal DH. If an elliptic curve group is used, such as ecp256, it's EC-based DH. Some other curves may be used:
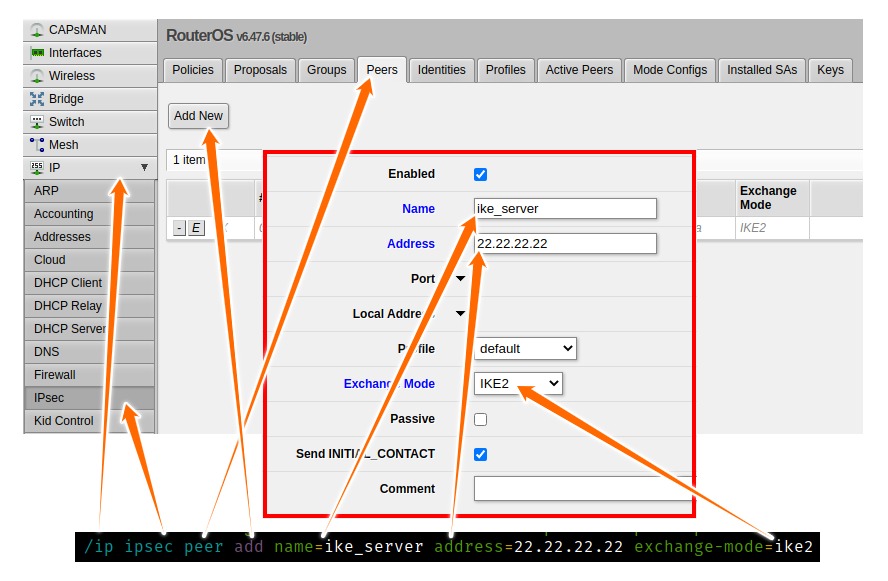
需要导入三个文件,先 scp 进 RouterOS 再/certificate import file-name=xxx.pem即可,WebUI也行。导入后确认 CA 证书显示为T,客户端证书显示为KT。
客户端私钥
客户端证书
CA 证书
1 2 3 4 5
[admin@RouterOS] > /certificate print Flags: K - private-key, L - crl, C - smart-card-key, A - authority, I - issued, R - revoked, E - expired, T - trusted # NAME COMMON-NAME SUBJECT-ALT-NAME 0 K T routeros.pem_0 routeros DNS:routeros.server.dns.name 1 T ca-cert.pem_0 ca
#--- Reversed DNS notation, iOS requires these. flags.DEFINE_string("profile_rdns", None, "Not displayed, but can be used to replace old profile.") flags.DEFINE_string("vpn_rdns", None, "Not displayed. Can be arbitrary string.") flags.DEFINE_string("client_cert_rdns", None, "Not displayed. Can be arbitrary string.") flags.DEFINE_string("ca_cert_rdns", None, "Not displayed. Can be arbitrary string.") #--- Strings to be displayed. Can be anything. flags.DEFINE_string("profile_display_name", None, "Arbitrary descriptive name.") flags.DEFINE_string("vpn_display_name", None, "Arbitrary descriptive name.") flags.DEFINE_string("client_cert_display_name", None, "Arbitrary descriptive name.") flags.DEFINE_string("client_cert_file_name", None, "Arbitrary descriptive name.") flags.DEFINE_string("ca_cert_display_name", None, "Arbitrary descriptive name.") flags.DEFINE_string("vpn_profile_name", None, "Arbitrary descriptive name.") #--- Server config flags.DEFINE_string("server_addr", None, "Domain name of the server.") flags.DEFINE_string("server_id", None, "Remote id. iOS always send this as FQDN type.") #--- Client config flags.DEFINE_string("client_cert_p12_file", None, "Client cert p12 file.") flags.DEFINE_string("client_cert_p12_pwd", None, "Password for client p12 cert.") flags.DEFINE_string("client_id", None, "Client's ID to be sent to the server. iOS always send this as FQDN type.") #--- CA config flags.DEFINE_string("ca_cert_pem_file", None, "CA cert file, not p12 format.") flags.DEFINE_string("ca_common_name", None, "CA's Common name. iOS will send a CERTREQ iff this value MATCHES the CA's common name") #--- iOS on-demand settings flags.DEFINE_bool("always_on_wifi", False, "Setup on-demand rules to always connect on WiFi") #--- Everything is required except client_cert_p12_pwd flags.mark_flag_as_required("profile_rdns") flags.mark_flag_as_required("vpn_rdns") flags.mark_flag_as_required("client_cert_rdns") flags.mark_flag_as_required("ca_cert_rdns")
defload_pem_file(fname:str)->bytes: with open(fname, "r") as f: lines = [l.strip() for l in f.read().split("\n")] lines = filter(lambda l:len(l) > 0and'-----'notin l, lines) return base64.b64decode(''.join(lines))
defsecurity_parameter_payload(): ret = dict() # Please check Apple's doc for the iOS version supporting these options # https://developer.apple.com/documentation/networkextension/nevpnikev2encryptionalgorithm ret["EncryptionAlgorithm"] = "AES-256-GCM" ret["IntegrityAlgorithm"] = "SHA2-256" ret["DiffieHellmanGroup"] = 19# ecp256 return ret
defikev2_payload(client_cert_uuid:str): ret = dict() ret["RemoteAddress"] = FLAGS.server_addr # iOS have bug with DN? # use server address as suggested ret["RemoteIdentifier"] = FLAGS.server_id ret["LocalIdentifier"] = FLAGS.client_id if FLAGS.ca_common_name isnotNone: ret["ServerCertificateIssuerCommonName"] = FLAGS.ca_common_name ret["AuthenticationMethod"] = "Certificate" ret["PayloadCertificateUUID"] = client_cert_uuid ret["CertificateType"] = "ECDSA256" ret["IKESecurityAssociationParameters"] = security_parameter_payload() ret["ChildSecurityAssociationParameters"] = security_parameter_payload() if FLAGS.always_on_wifi: # https://developer.apple.com/documentation/networkextension/personal_vpn/vpn_on_demand_rules ret["OnDemandEnabled"] = 1 ret["OnDemandRules"] = [ dict(InterfaceTypeMatch="WiFi", Action="Connect"), dict(Action="Ignore") ]
strongSwan 在尝试匹配 ID 和证书的时候会检查 Subject DN 和 SubjectAltName (SAN)。我们之前一直在使用 Subject DN,而 SAN 则允许我们使用域名甚至 IP 作为 ID。另外,虽然我一直称呼“域名”或是“IP”,但是实际上只要 SAN 和 ID 匹配即可,这个“域名”到底是不是我们的并没有关系。(当然只有自签才能签出这种证书)
Subject Alternative Name
要颁发带有 SAN 的证书只需要在 tmpl 文件(参见 Part2)中添加如下内容:
# 域名 SANdns_name="san.hosta.com"# IP 地址 SANip_address = "fd00::1"
需要注意的是,SAN 是区分类型的,比如上文的 DNS 和 IP,而 IKEv2 使用的 ID 也是分类型的(FQDN,IP,etc.)。类型需要匹配才能认证成功。有的教程会使用形如@xxx.xxx.xx.x这样的 IP,可能原因是,某些客户端使用 IP 作为 ID 但是却标记为 FQDN,或者是生成证书的时候将 IP 标记成了域名 SAN。这种情况就需要给 IP 添加前缀@来强制让 strongSwan 将其当作域名 ID。具体的解析规则可见 Identity Parsing 文档。
另外,这次我们会在服务器上配置 NAT,所以不再需要手动在服务端配置一个 IP 了。假设服务端eth0接口的公网 IP 是2000::1。首先将ca-cert.pem,server-key.pem,server-cert.pem三个文件移动到服务器上正确的地方。然后编写配置文件,同样的,这里只注释和 Part4 中不同的地方。
接 Part3,有了 Tunnel 模式以后我们实际使用的 IP 地址就不用受制于机器的实际 IP 了。但是手动给每个客户端手动分配一个地址显然是不切实际的。于是我们可以使用 Virtual IP 功能自动向连入的客户端分配一个内网 IP,就像 DHCP 或者 SLAAC 那样。
场景配置
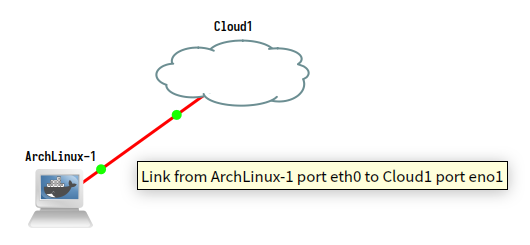
与之前完全对称的配置不同,使用 Virtual IP 时需要区分服务端和客户端。先在服务端配置将要分配的 IP,然后由客户端发起连接,服务端就会将配置好的 IP 分发出去。我使用 HostA 作为服务端,HostB 作为客户端。HostA 将会给 HostB 分配 IPv4 与 IPv6 各一个。使用的 Virtual IP 段是fd01::100-fd01::200和10.10.10.100-10.10.10.150。
hosta$ ip -br addreth1 UP fd00::1/64 fd01::1/128 10.10.10.1/32hostb$ ip -br addreth1 UP fd00::2/64
和 Part3 相比,HostA 这里有一些与之前不同的地方,一是内部 IP 全部放在了 eth1 上(而不是 lo 上);二是内部 IP 的前缀长度都是最大值;三是增加了一个 IPv4 的内部 IP,用于和分配的 IPv4 Virtual IP 通信。同时 HostB 也不再手工分配fd01开头的内部 IP 了,将由 strongSwan 自动配置。
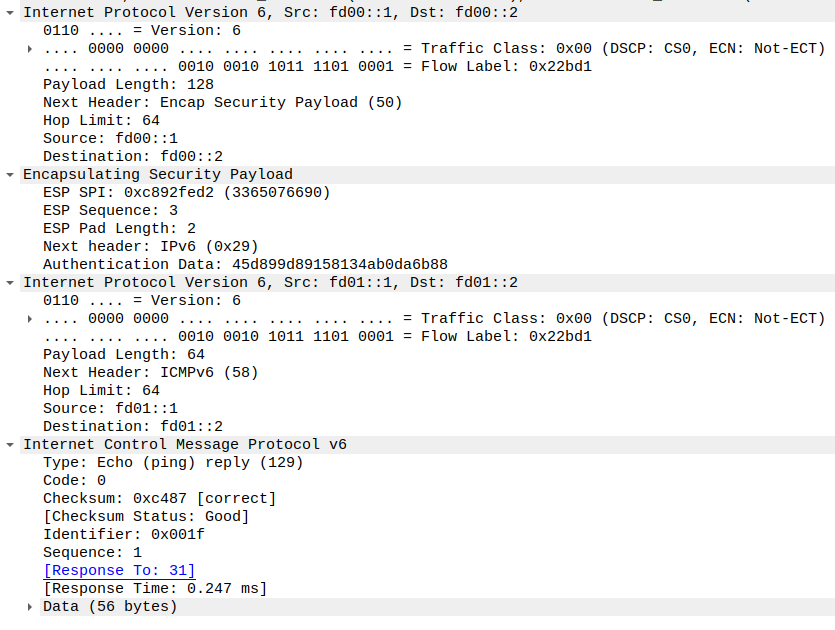
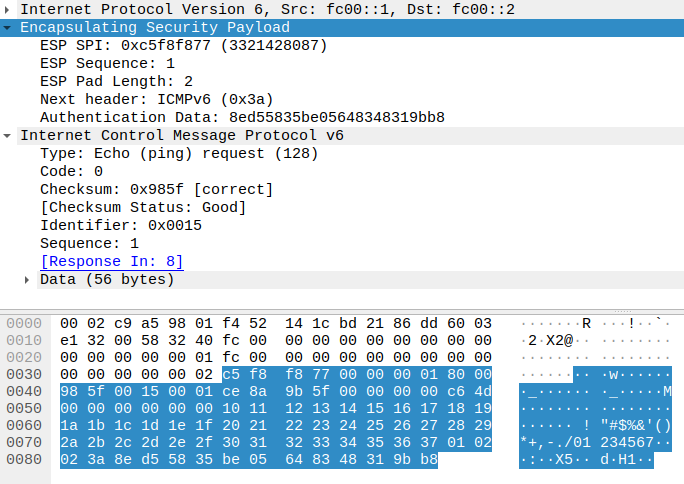
前两篇中我们使用的都是 Transport 模式,但是实际使用中,更常用的是 Tunnel 模式。Transport 模式只加密四层及以上数据,而不修改 IP 头,原始的 IP 头将会原样传输。这意味着我们只能进行点对点传输,因为只有一个 IP 头,我们无法告知对方服务器我们实际要访问的地址。Tunnel 模式则是连原始的 IP 头也一起加密,然后再在前端添加一个新的 IP 头,这样服务器在收到数据包后,可以解密并读取内部的 IP 头,再转发给实际的目标服务器。
]]>
<p>第三篇简单介绍一下 IPsec 的 Tunnel 模式,没看过前两篇的快去看~<br><a href="/2020/10/ipsec-configurations-part1/">Part1 传送门</a>;<a href="/2020/10/ipsec-configurations-part2/">Part2 传送门</a></p>
<h2 id="Tunnel-模式简介"><a href="#Tunnel-模式简介" class="headerlink" title="Tunnel 模式简介"></a>Tunnel 模式简介</h2><p><img src="/images/ipsec-configurations-part3/01-tunnel-mode-header-layout.png" alt="Tunnel mode header layout"> 前两篇中我们使用的都是 Transport 模式,但是实际使用中,更常用的是 Tunnel 模式。Transport 模式只加密四层及以上数据,而不修改 IP 头,原始的 IP 头将会原样传输。这意味着我们只能进行点对点传输,因为只有一个 IP 头,我们无法告知对方服务器我们实际要访问的地址。Tunnel 模式则是连原始的 IP 头也一起加密,然后再在前端添加一个新的 IP 头,这样服务器在收到数据包后,可以解密并读取内部的 IP 头,再转发给实际的目标服务器。</p>
IPsec 配置备忘 Part2 - 证书https://recursiveg.me/2020/10/ipsec-configurations-part2/2020-10-30T15:50:00.000Z2020-12-05T22:13:32.162Z作为系列的第二篇文章,讲解基本的证书原理和配置方法。没看过第一部分的快去看~ 传送门:IPsec 配置备忘 Part1。
证书认证基础
我们在 Part1 中看到,PSK 认证的基本思路是使用一个只有通信双方才知道的暗号,如果能确认对方确实知道这个暗号,那么认证就成功了。证书认证的思路非常不同:假设 A 需要向 B 证明自己的身份,同时 A 知道 B 信任 C,那么 A 可以向 C 索取一份“介绍信”,当 B 询问 A 的身份时,A 可以向 B 展示这份 C 出具的“介绍信”,如果 B 能够确认这份“介绍信”确实是由 C 出具的,那么认证就成功了。注意这个认证是单向的,假设 A 也信任 C,那么 B 也可以通过向 C 索取“介绍信”来向 A 证明自己的身份。在 PKI 体系中,A 和 B 持有各自的“私钥”,C 作为 Certificate Authority (CA) 向 A/B 颁发证书(即“介绍信”)。同时,CA 也会向自己颁发一份证书并分发给 A/B,A/B 使用 CA 的证书来确认 B/A 出示的证书确实为 C 所颁发。
]]>
<p>作为系列的第二篇文章,讲解基本的证书原理和配置方法。没看过第一部分的快去看~<br>传送门:<a href="/2020/10/ipsec-configurations-part1/">IPsec 配置备忘 Part1</a>。</p>
<h2 id="证书认证基础"><a href="#证书认证基础" class="headerlink" title="证书认证基础"></a>证书认证基础</h2><p>我们在 Part1 中看到,PSK 认证的基本思路是使用一个只有通信双方才知道的暗号,如果能确认对方确实知道这个暗号,那么认证就成功了。证书认证的思路非常不同:假设 A 需要向 B 证明自己的身份,同时 A 知道 B 信任 C,那么 A 可以向 C 索取一份“介绍信”,当 B 询问 A 的身份时,A 可以向 B 展示这份 C 出具的“介绍信”,如果 B 能够确认这份“介绍信”确实是由 C 出具的,那么认证就成功了。注意这个认证是单向的,假设 A 也信任 C,那么 B 也可以通过向 C 索取“介绍信”来向 A 证明自己的身份。在 PKI 体系中,A 和 B 持有各自的“私钥”,C 作为 Certificate Authority (CA) 向 A/B 颁发证书(即“介绍信”)。同时,CA 也会向自己颁发一份证书并分发给 A/B,A/B 使用 CA 的证书来确认 B/A 出示的证书确实为 C 所颁发。</p>
IPsec 配置备忘 Part1 - IKEv2 基础https://recursiveg.me/2020/10/ipsec-configurations-part1/2020-10-29T15:40:00.000Z2021-01-19T04:10:19.549Z俗话说得好,配置 IPsec 隧道只有零次和无数次,在被 strongSwan 折磨了 N 次以后,我终于决定要把之前试过的配置都记录下来,于是就有了这个系列。我计划基本上每个 PART 会介绍一个(或几个)特定场景下的配置,配置文件样例以 strongSwan vici 为主,之后可能会介绍 iOS, Android 或者是 Mikrotik 路由器的配置方法,如果我能坚持不鸽写到那里的话(画外音:你这 FLAG 立得……)FLAG 回收了。如果各位有想看的配置场景欢迎留言告诉我,会考虑先写。
IKEv2 与 IPsec 基础
严格来说 IKEv2 不是 VPN,它的全称是 Internet Key Exchange,只是一种用于交换密钥的协议罢了。密钥在计算机里一般就表示为一串固定长度的二进制数据,密钥交换就是指在两台设备之间约定一个相同的二进制串,就像两个密友之间约定暗号一样。一旦密钥交换完毕,IKE 的使命就结束了,具体怎么用约定好的密钥加密数据不是 IKE 解决的问题。在 Linux 系统上,实际的数据包加密解密是由内核的 XFRM 框架负责的,你可以使用ip xfrm命令看到配置好的密钥以及加解密使用的算法。事实上,不使用 IKEv2 而完全手动“交换”密钥是可行的,比如朴素VPN:一个纯内核级静态隧道。你可以看到作者直接使用ip xfrm {policy,state} add指令设定密钥,然后内核就会自动用设定的密钥加密流量。
内核 XFRM 的工作方式和基于 TUN 设备的 VPN 很不一样。一般基于 TUN 的 VPN 会加密所有进入 TUN 设备的流量,因此你可以直接使用路由表来控制哪些流量走 VPN,哪些不走。而 XFRM 的匹配基于策略(i.e. 源地址+目标地址+一些别的),如果某个数据包匹配到了一个策略,这个数据包就会根据这个策略指定的方式被加密。
比方说有A [fd00::1]和B [fd00::2],如果你从 A 发送一个数据包到 B,普通情况下这个数据包是明文的。如果你在 A 配置了src=fd00::1,dst=fd00::2,encrypt=<...>的策略并再发一个数据包,这个包就会自动被加密。B 收到了这个数据包,但是它并不知道该如何解密,所以你必须同时在 B 配置一条src=fd00::1,dst=fd00::2,decrypt=<...>的策略,这样 B 才能解密。对于从 B 到 A 的流量也需要类似的两条策略。使用 IKEv2 的话,这些策略 strongSwan 都会自动帮你设置好,无需操心。于是你会发现,尽管我们仍然在使用节点本身的 IP,但是流量却已经被加密了。
]]>
<p>俗话说得好,配置 IPsec 隧道只有零次和无数次,在被 strongSwan 折磨了 N 次以后,我终于决定要把之前试过的配置都记录下来,于是就有了这个系列。我计划基本上每个 PART 会介绍一个(或几个)特定场景下的配置,配置文件样例以 strongSwan vici 为主,之后可能会介绍 iOS, Android 或者是 Mikrotik 路由器的配置方法,<del>如果我能坚持不鸽写到那里的话(画外音:你这 FLAG 立得……)</del> <a href="/2021/01/ipsec-configurations-part9/">FLAG 回收了</a>。如果各位有想看的配置场景欢迎留言告诉我,会考虑先写。</p>
<h2 id="IKEv2-与-IPsec-基础"><a href="#IKEv2-与-IPsec-基础" class="headerlink" title="IKEv2 与 IPsec 基础"></a>IKEv2 与 IPsec 基础</h2><p>严格来说 IKEv2 不是 VPN,它的全称是 Internet Key Exchange,只是一种用于交换密钥的协议罢了。密钥在计算机里一般就表示为一串固定长度的二进制数据,密钥交换就是指在两台设备之间约定一个相同的二进制串,就像两个密友之间约定暗号一样。一旦密钥交换完毕,IKE 的使命就结束了,具体怎么用约定好的密钥加密数据不是 IKE 解决的问题。在 Linux 系统上,实际的数据包加密解密是由内核的 XFRM 框架负责的,你可以使用<code>ip xfrm</code>命令看到配置好的密钥以及加解密使用的算法。事实上,不使用 IKEv2 而完全手动“交换”密钥是可行的,比如<a href="https://gist.github.com/blackgear/a9f96261b091b2215dfd" target="_blank" rel="noopener">朴素VPN:一个纯内核级静态隧道</a>。你可以看到作者直接使用<code>ip xfrm {policy,state} add</code>指令设定密钥,然后内核就会自动用设定的密钥加密流量。</p>
<p>然而,手动管理内核状态是复杂的,人工分发密钥也不怎么安全,这时就轮到 strongSwan 登场啦(或者说,任何实现了 IKE 的 Daemon 服务)。两台服务器的 strongSwan 使用 IKEv2 协议交换密钥,解决了密钥分发的问题。随后 strongSwan 会把交换得来的密钥设定进内核,这样内核就会自动加密指定的流量了。</p>
<p>从数据包层面上看,IKE 是7层协议,密钥交换使用特殊的 UDP 包完成。而一般被加密的数据包会使用 ESP 封装,ESP 头一般紧跟在 IP 头后。ESP 也可以被封装进 UDP 用以穿越 NAT。</p>
<h2 id="没有-TUN-设备"><a href="#没有-TUN-设备" class="headerlink" title="没有 TUN 设备"></a>没有 TUN 设备</h2><p>内核 XFRM 的工作方式和基于 TUN 设备的 VPN 很不一样。一般基于 TUN 的 VPN 会加密所有进入 TUN 设备的流量,因此你可以直接使用路由表来控制哪些流量走 VPN,哪些不走。而 XFRM 的匹配基于策略(i.e. 源地址+目标地址+一些别的),如果某个数据包匹配到了一个策略,这个数据包就会根据这个策略指定的方式被加密。</p>
<p>比方说有<code>A [fd00::1]</code>和<code>B [fd00::2]</code>,如果你从 A 发送一个数据包到 B,普通情况下这个数据包是明文的。如果你在 A 配置了<code>src=fd00::1,dst=fd00::2,encrypt=<...></code>的策略并再发一个数据包,这个包就会自动被加密。B 收到了这个数据包,但是它并不知道该如何解密,所以你必须同时在 B 配置一条<code>src=fd00::1,dst=fd00::2,decrypt=<...></code>的策略,这样 B 才能解密。对于从 B 到 A 的流量也需要类似的两条策略。使用 IKEv2 的话,这些策略 strongSwan 都会自动帮你设置好,无需操心。于是你会发现,尽管我们仍然在使用节点本身的 IP,但是流量却已经被加密了。</p>
<p>对于那些必须使用路由表或是策略匹配不是很有效的场景, <a href="https://wiki.strongswan.org/projects/strongswan/wiki/RouteBasedVPN" target="_blank" rel="noopener">Route-based IPsec VPN</a> 也是存在的。我也许会在未来的某一期讲。</p>
Linux + Windows 10 多系统安装 U 盘https://recursiveg.me/2020/10/linux-windows-multiboot-usb/2020-10-24T16:50:00.000Z2020-11-05T00:06:24.634Z
Update: Windows 的引导程序似乎有些问题,如果在同一块 U 盘上写入多个 ISO 分区的话,似乎引导会错乱,最终启动的安装程序版本不是引导程序所在分区的版本。所以暂时一个 U 盘还是只能放一个 Windows 版本。垃圾巨硬。
日常折腾中总免不了要用 LiveCD 修理一下系统,或者是重装一下 Windows 之类的。这时候制作一个引导用的 U 盘基本是最方便的选项了。有不少工具都能创建 U 盘引导,比如 ArchLinux 的 ISO 镜像可以直接用dd写入,Windows 的安装盘也能用 Rufus 创建。不过在使用上还是有些不便,比如dd会覆盖整个U盘,在ISO之外不能再存储其他文件。Rufus 只能在 Windows 上运行,而且一只 U 盘也只能放一份 ISO。于是尝试搞明白怎么把 Linux 的 LiveCD 和 Windows 的安装 ISO 写入到同一只 U 盘就很有必要了。
我个人使用的设备都支持 UEFI,所以这里制作的启动盘也只支持 UEFI 启动,需要 MBR 模式启动的读者请往它处寻。当然,Secure Boot 是要关掉的。制作过程我使用 Linux,纯 Windows 用户现在也可以退出了。基本上,我们需要创建一个 EFI 系统分区(EFI System Partition, ESP),其中包含基本的引导程序(Grub2)和 Linux LiveCD 的 ISO 文件。由于 Windows 的安装程序无法以 ISO 形式被引导,因此我们需要给每个 Windows ISO 文件创建一个分区,并将 ISO 中的内容解压进去。但是分区一旦创建不像文件那么好修改,所以创建每个 Windows ISO 分区的时候我都留了一些额外空间,以备以后 ISO 大小变化,这也意味着这些空间就基本浪费了。That's sad but I guess it's how things work.
另外,购买一个优质的 U 盘还是有必要的,不然不管是创建启动盘还是安装系统都会慢得让你痛不欲生。建议用之前先给 U 盘测一下速,什么拷贝速度只有 2MB/s 的金士顿可以直接进垃圾桶了。至于 U 盘大小取决于你要放多少个 ISO 文件和多少个 Windows 分区,一般 Linux 镜像大小在 500MB~3GB 的都有,Windows 10 的分区一般每个需要 5~6GB.
先给 U 盘分区,用fdisk或者别的什么工具都行。我用的 32GB 的 U 盘,分了 6GB 给 ESP,然后是另外两个 6GB 的分区给 Windows 10 的安装程序。剩下空间留着给以后使用。
]]>
<blockquote>
<p><strong><em>Update:</em></strong> Windows 的引导程序似乎有些问题,如果在同一块 U 盘上写入多个 ISO 分区的话,似乎引导会错乱,最终启动的安装程序版本不是引导程序所在分区的版本。所以暂时一个 U 盘还是只能放一个 Windows 版本。垃圾巨硬。</p>
</blockquote>
<p>日常折腾中总免不了要用 LiveCD 修理一下系统,或者是重装一下 Windows 之类的。这时候制作一个引导用的 U 盘基本是最方便的选项了。有不少工具都能创建 U 盘引导,比如 ArchLinux 的 ISO 镜像可以直接用<code>dd</code>写入,Windows 的安装盘也能用 <a href="https://rufus.ie" target="_blank" rel="noopener">Rufus</a> 创建。不过在使用上还是有些不便,比如<code>dd</code>会覆盖整个U盘,在ISO之外不能再存储其他文件。Rufus 只能在 Windows 上运行,而且一只 U 盘也只能放一份 ISO。于是尝试搞明白怎么把 Linux 的 LiveCD 和 Windows 的安装 ISO 写入到同一只 U 盘就很有必要了。</p>
<p>我个人使用的设备都支持 UEFI,所以这里制作的启动盘也只支持 UEFI 启动,需要 MBR 模式启动的读者请往它处寻。当然,Secure Boot 是要关掉的。制作过程我使用 Linux,纯 Windows 用户现在也可以退出了。基本上,我们需要创建一个 EFI 系统分区(EFI System Partition, ESP),其中包含基本的引导程序(Grub2)和 Linux LiveCD 的 ISO 文件。由于 Windows 的安装程序无法以 ISO 形式被引导,因此我们需要给每个 Windows ISO 文件创建一个分区,并将 ISO 中的内容解压进去。但是分区一旦创建不像文件那么好修改,所以创建每个 Windows ISO 分区的时候我都留了一些额外空间,以备以后 ISO 大小变化,这也意味着这些空间就基本浪费了。That's sad but I guess it's how things work.</p>
<p>另外,购买一个优质的 U 盘还是有必要的,不然不管是创建启动盘还是安装系统都会慢得让你痛不欲生。建议用之前先给 U 盘测一下速,什么拷贝速度只有 2MB/s 的金士顿可以直接进垃圾桶了。至于 U 盘大小取决于你要放多少个 ISO 文件和多少个 Windows 分区,一般 Linux 镜像大小在 500MB~3GB 的都有,Windows 10 的分区一般每个需要 5~6GB.</p>
在 Raspberry Pi 4B 上安装 ArchLinuxhttps://recursiveg.me/2020/10/archlinux-on-raspberrypi-4b/2020-10-03T05:50:00.000Z2020-10-30T03:57:48.330Z 很久之前就买了一个树莓派,不过一直在吃灰,正好最近有空就再拿出来折腾一下。原装系统是 32 位的,那么就必定要换一个 64 位的啦,不然对不起这 64 位的 CPU 呀。秉承“Arch大法好”的理念,我就决定用 Archlinux ARM 了。我非常建议先用原版系统更新 Bootloader 和 EEPROM到最新版本。这样可以避免各种奇怪的 bug 和使用一些新加入的功能,比如从网络启动什么的。
# Ninja does not work with backward-cpp new_bin() { local name="$1" mkdir "$name" || die cd"$name" || die git clone'https://github.com/fmtlib/fmt.git' third_party/fmt || die git clone'https://github.com/bombela/backward-cpp.git' third_party/backward-cpp || die git clone'https://github.com/gabime/spdlog.git' third_party/spdlog || die cat << EOF > CMakeLists.txt cmake_minimum_required(VERSION 3.11) project(${name})
linux-5.5-rc5$ make x86_64_defconfig # 使用64位默认配置...此处省略若干行...linux-5.5-rc5$ make -j10 # 请根据你电脑的核心数量调整...此处省略若干行...Kernel: arch/x86/boot/bzImage is ready (#1)
GHCi, version 8.6.3: http://www.haskell.org/ghc/ :? for help [1 of 1] Compiling Main ( helloworld.hs, interpreted ) Ok, one module loaded. *Main> foo "hello, world" *Main>
-- 接受一个整型参数,返回一个新函数。这个新函数接受一个整型,返回一个整型 product' :: Int -> (Int -> Int) product' x y = x * y timesThree = product' 3 nine = timesThree 3 nine' = (product' 3) 3
-- 接受一个参数,该参数是“接受一个整型,返回一个整型”的函数,然后返回一个整型 some_func :: (Int -> Int) -> Int some_func f = f 42 -- *Main> some_func (* 2) -- 84
dataTupleOf a = MakeTupleOf a a -- MakeTupleOf :: a -> a -> TupleOf a -- MakeTupleOf False True :: TupleOf Bool -- MakeTupleOf 1 2 :: Num a => TupleOf a -- MakeTupleOf plus1 plus2 :: Num a => TupleOf (a -> a)
-- 你可以使用函数的模式匹配来提取数据结构中的成员 printNameAndAge :: NameAndAge -> String printNameAndAge (MakeNameAndAge name age) = "I'm " ++ name ++ " and I'm " ++ (show age) ++ " years old."
-- 你也可以使用模式匹配来判断是哪一个构造函数 printIntOrBool :: IntOrBool -> String printIntOrBool (MakeInt n) = "Wow, an integer: " ++ (show n) printIntOrBool (MakeBool b) = "Wow, a boolean: " ++ (show b)
-- 你甚至可以进行递归类型定义 。当然,你需要一个终止条件。 dataListOf a = EmptyList | AppendList (ListOfa) a
-- 相关操作也需要使用递归函数来完成 contains :: (Eq a) => ListOf a -> a -> Bool containsEmptyList _ = False contains (AppendList list x') x = if x == x' thenTrueelse contains list x
*Main> :info Eq class Eq a where (==) :: a -> a -> Bool (/=) :: a -> a -> Bool {-# MINIMAL (==) | (/=) #-} -- Defined in ‘GHC.Classes’ instance [safe] Eq a => Eq (ListOf a) -- Defined at [omitted] [... omitted ...]
*Main> :info Monad classApplicative m => Monad (m :: * -> *) where (>>=) :: m a -> (a -> m b) -> m b (>>) :: m a -> m b -> m b return :: a -> m a fail :: String -> m a
简化一下
1 2 3
classMonad m where (>>=) :: m a -> (a -> m b) -> m b return :: a -> m a
当我们说Maybe是一个Monad的时候,一方面指 Maybe 属于 Monad 这个类型类instance Monad Maybe where ...。另一方面指Maybe(数据结构),(>>=)::Maybe a -> (a -> Maybe b) -> Maybe b (函数),return::a -> Maybe a (函数)这三者构成了一个满足某些条件的数学结构,这些条件被称为Monad Laws。事实上,Haskell编译器不会检查 Monad Laws 是否满足,你可以胡乱写一些数据结构和函数,然后将其塞入 Monad 这个类型类中。换句话说,Haskell中的Monad就是一个接口,任何实现接口的数据类型都可以称其为Monad。
回到Maybe上,现在你想把这两个会失败的函数连接在一起
1 2 3 4 5 6 7
func3 :: Float -> MaybeBool -- 错误示范,类型不匹配 -- func3 = func2.func1 -- 正确示范 func3 n = case (func1 n) of Nothing -> Nothing Just n' -> func2 n'
看上去不错,我们需要一种操作,能把任意两个可失败的函数连在一起,这样以后再碰到这种情况直接复用就行了。如果第一个函数类型是a->Maybe b,第二个函数类型是b->Maybe c,那么复合函数的类型应该是a->Maybe c
1 2 3 4 5 6 7
composite :: (b -> Maybe c) -> (a -> Maybe b) -> (a -> Maybe c) composite f g = \x -> case g x of Nothing -> Nothing Just y -> f y
if (page_require_modification()) { var content = document.getElementById("hidden-div").innerHTML; var clean_content = document.createElement("p"); clean_content.append(document.createTextNode(content)); document.getElementById("main-div").append(clean_content); }
ip tunnel add gre-tunnel mode gre remote $client_ipv4 ttl 64 ip link set gre-tunnel up ip addr add a:b:c:d:e::1/80 dev gre-tunnel
第一行建立隧道,gre-tunnel是隧道名称,可以按自己喜欢的来,记得其他的也要一起改
第二行激活隧道
第三行分配IP地址
本地配置
脚本如下,和服务端配置几乎一样,同样需要root:
1 2 3 4
ip tunnel add gre-tunnel mode gre remote $server_ipv4 ttl 64 ip link set gre-tunnel up ip addr add a:b:c:d:e::2/80 dev gre-tunnel ip -6 route add default dev gre-tunnel
第一行建立隧道,隧道名称不必和服务器的一样
第二行激活隧道
第三行分配IP地址,注意不要和服务器的冲突,这个IP也是将要暴露在网络上的IP
第四行设定路由,让IPv6流量都走隧道
访问网络
现在,两台机器应该可以互ping了。有的比较奇葩的情况可能需要手动ip link set gre0 up一下,gre0似乎是内核模块自动加入的玩意儿,具体怎么回事我也不清楚–_–| 但是现在还不能访问外网,还需要在服务器执行以下命令:
1 2 3
sysctl net.ipv6.conf.all.forwarding=1 sysctl net.ipv6.conf.all.proxy_ndp=1 ip -6 neigh add proxy a:b:c:d:e::2 dev eth0
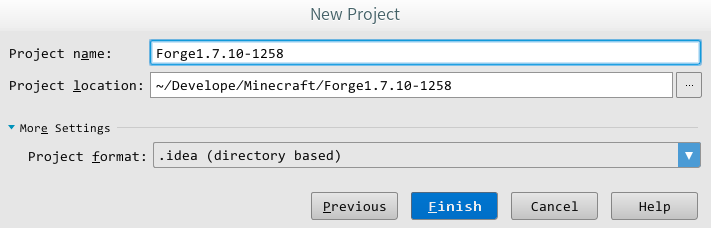
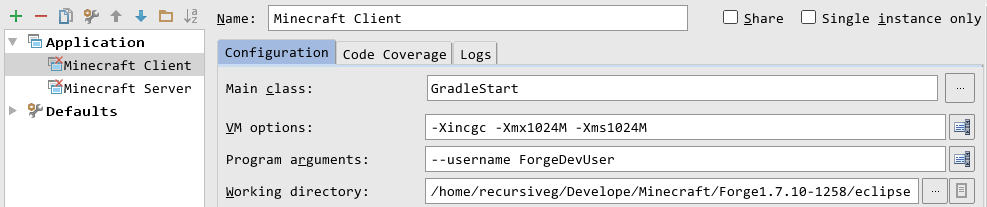
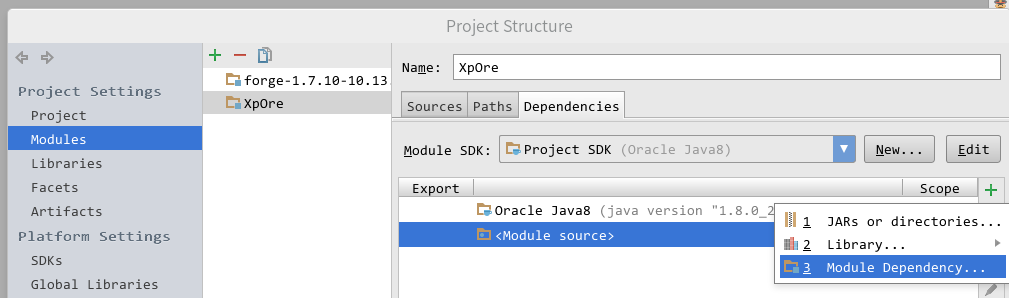
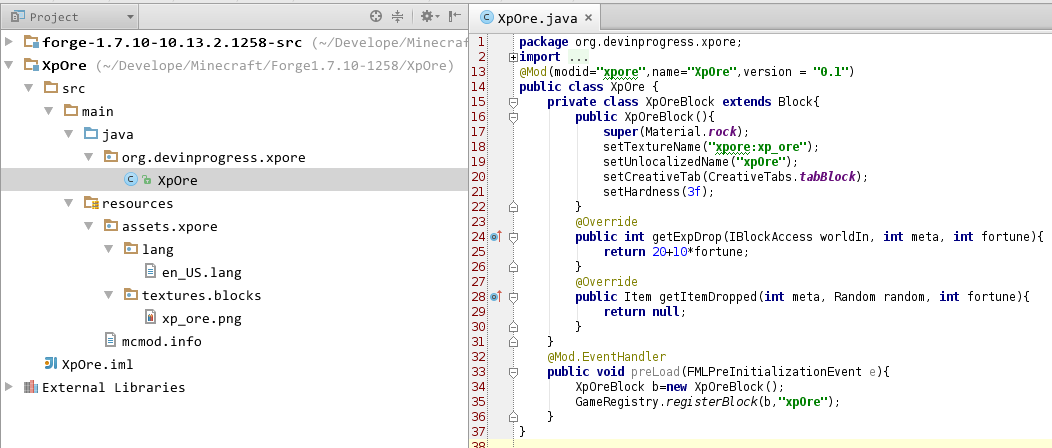
要想让这个Mod在IDEA里运行起来,有两种方式。第一种比较简单,直接菜单栏”Run –> Edit Configurations –> ‘Minecraft Client’ –> Use classpath of mod …”下拉列表里选”XpOre”,保存退出运行即可。这种方式比较适合只开发一个Mod的情况。 当有N个Module互相依赖的时候,我推荐创建另一个Module,比方说,叫”Run”。然后令其依赖forge-1.7.10-10.13.2.1258-src和你需要加载的其他Module,然后”Use classpath of mod”选择”Run”即可。
public net.minecraft.entity.EntityList func_75618_a(Ljava/lang/Class;Ljava/lang/String;I)V public net.minecraft.entity.EntityList field_75625_b #nameToClassMap public net.minecraft.item.crafting.CraftingManager func_92103_a(Lnet.minecraft.item.ItemStack;[Ljava/lang/Object;)Lnet.minecraft.item.crafting.ShapedRecipes;
接着重建工作区:
gradle clean setupDecompWorkspace idea --refresh-dependencies
]]>
Sixth part of serial of tutorial: Programming with PTRACE
Programming with PTRACE, Part5 - 内存管理https://recursiveg.me/2014/05/programming-with-ptrace-part5/2014-05-26T02:00:32.000Z2020-01-12T19:04:29.750Z这个part主要讲解Linux的内存管理机制,以及如何查看并限制子进程的内存使用。
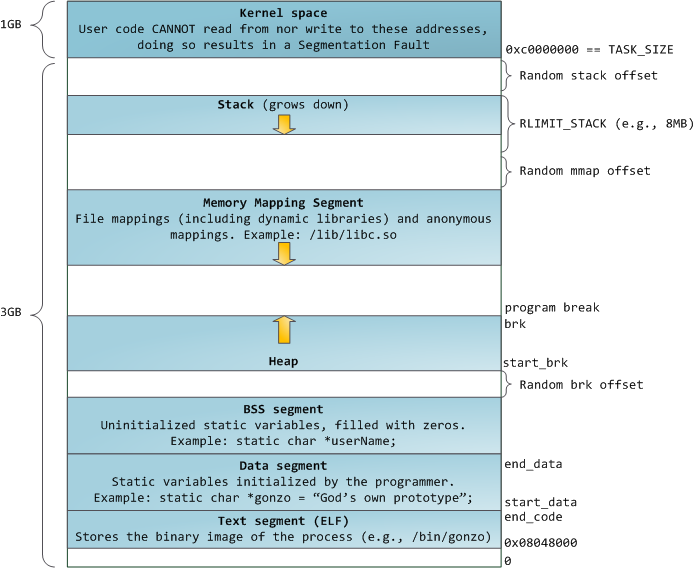
还记得之前的rusage结构么?其成员可在这里找到。事实上,这是一种非常简陋的内存使用信息获取方式,我们只关心其中的ru_maxrss一项,RSS即”Resident Set Size”,表示该进程在物理内存中的占用大小,不包括交换分区中的内存大小,也不包含分配了却未使用而没有物理内存页的内存。为了获得更详细的内存信息,我们需要访问/proc目录。该目录下各文件的用途在man 5 proc里描述得很清楚,这里是网页版本。关于这个目录的作用,我就偷懒,将man手册中的描述翻译如下:
]]>
Fifth part of serial of tutorial: Programming with PTRACE
Programming with PTRACE, Part4 - 系统调用进阶https://recursiveg.me/2014/05/programming-with-ptrace-part4/2014-05-26T02:00:31.000Z2020-01-12T19:04:29.316Z这个part是Part2的延续,所以我强烈建议你弄明白Part2中的内容后再来看本part。那么进入正题,我将在这个部分讲解系统调用的参数传递顺序以及如何利用ptrace系统调用获得用户空间的数据。
]]>
Fourth part of serial of tutorial: Programming with PTRACE
Programming with PTRACE, Part3 - 进程的终止与信号https://recursiveg.me/2014/05/programming-with-ptrace-part3/2014-05-25T10:26:20.000Z2020-01-12T19:04:28.883Z在Part2中,我们粗略了解了如何使用ptrace获得系统调用信息,即在一个大循环里不断获取程序信息,如果程序退出则停止循环。当然,那个判断异常简陋,几乎无法处理任何特殊情况。我将在本Part中详细解说各种异常情况的处理,同时讲解各种信号相关的问题。
wait4(pid,&sta,0,&ru); if(WIFEXITED(sta)){printf("Exited with code %d",WEXITSTATUS(sta));break;} if(WIFSIGNALED(sta)){printf("Terminated by signal: %s",strsignal(WTERMSIG(sta)));break;} int sig_no; if(WIFSTOPPED(sta))sig_no=WSTOPSIG(sta); if(sig_no==SIGTRAP)sig_no=0; ...... ptrace(PTRACE_SYSCALL,pid,0,sig_no);
]]>
Third part of serial of tutorial: Programming with PTRACE
Programming with PTRACE, Part2 - 系统调用入门https://recursiveg.me/2014/04/programming-with-ptrace-part2/2014-04-20T12:00:19.000Z2020-01-12T19:04:28.450Z在这部分,我会介绍如何使用ptrace监控子进程的系统调用。我先将完整代码列在开头,你现在十有八九看不懂它,但我希望你在看完这篇文章后能彻底理解这段代码。(这段代码在64位系统上有效,32位系统请参照最后给32位系统的Tip手动修改源代码)
]]>
Second part of serial of tutorial: Programming with PTRACE
Programming with PTRACE, Part1 - 起步https://recursiveg.me/2014/04/programming-with-ptrace-part1/2014-04-17T13:16:29.000Z2020-01-12T19:20:08.943Z前言
本人作为一个信息学竞赛的参与者,在很久之前曾经试图自己写过一个Online Judge系统(允许用户上传源代码并在服务器上编译运行),考虑到安全因素,必须要对程序的行为进行限制,因此对ptrace进行了一番研究。网上有一份关于ptrace的很好的教程(Playing with ptrace),但是时间有点久了,而且没有涉及64位操作系统。因此,我决定写这份教程,基于64位Linux,尽力介绍一些新加入的功能,同时兼顾一下32位系统。另外,由于一开始的目的是“对程序的行为进行限制”,所以不会涉及到诸如设置断点之类的内容,相反,可能会涉及到其他关于系统资源管理的内容。 ptrace()是一个由Linux内核提供的系统调用。它允许一个用户态进程检查、修改另一个进程的内存和寄存器。这种技术被广泛用于gdb等调试器中。尽管这系列文章的标题叫做“Programming with PTRACE”,但在第一部分中,我将着重介绍Linux的进程和相关的几个重要函数。
#include<stdio.h> #include<unistd.h> intmain(int argc,char *argv[]){ int return_val; puts("Program started."); return_val=fork(); printf("fork() returned %d\n",return_val); return0; }
将会输出
Program started.fork() returned 5768fork() returned 0
很明显地可以看到,puts()只被调用了一次而printf()被调用了两次,这说明在fork()前的一个进程变成了两个,而且fork()在两个进程中有不同的返回值(这就是“调用一次,返回两次”的来历)。fork()会返回0给子进程,返回子进程的pid给父进程,因此,我们很容易判断出fork() returned 0是由子进程打印的。在实际应用中,也通过if语句判断返回值的方法来决定执行不同的代码:
int pid=fork();if (pid==0){ //子进程的工作}else{ //父进程的工作}
]]>
First part of serial of tutorial: Programming with PTRACE
有屏幕的地方就有烂苹果https://recursiveg.me/2014/03/bad-apple-character-player/2014-03-19T11:55:49.000Z2020-01-12T19:20:09.376Z如果你还不知道Bad Apple是什么东西,请移步这里 播放的原理很简单,就是不停的打印清屏再打印清屏。任何一个略有编程基础的人都能做到。比较令人头大的是如何把原视频转化为一个易于解析而且又不占地方的文件。 其实,借助FFmpeg、ImageMagick和一点点的编程小技巧就可以轻松完成。
为了解释这个问题,我要先引入Python3中的字符串与字节序列的概念。在Python3中,一个字符串不存在‘编码类型’这种概念,每一个包含相同文字的字符串都是完全一样的(确切的讲,Python3中的字符串是以Unicode编码的字节序列)。而字节序列和C中的char数组很像,它是字符串保存在文件系统上的真正形态。一个固定的字符串(即包含相同的文字)可以被编码(即Python中的encode())成字节序列。如果对其使用不同的编码方式,生成的字节序列也不同。举个例子,一栋房子地面上的第一层,英国人叫它’ground floor’,而美国人叫它‘first floor’。这就是不同的编码方式。相反,解码(Python中的decode())就是把一个字节序列变回字符串。在普通情况下,乱码是由于对一个字节序列使用了错误的编码方式进行解码,解码之后的内容自然无法阅读。就像一个英国人给一个美国人留了张便条,写着‘Meet me at first floor.’(二楼),然后美国人去一楼转了半天都没找到。这种使用了错误的解码方式的问题一般是由于操作系统的默认设定造成的,比如Windows系统使用当地语言的编码(大陆GBK,台湾BIG5,日本SHIFT-JIS之类的),而Linux普遍使用UTF-8编码。解决这种乱码的方法也很简单,你不是默认以UTF8方式解读么?而现在的字节序列又需要以GBK方式解读才能获得正确的内容,那么我们只要找到一个字节序列,让它被以UTF8解码时得到的内容和现在的字节序列被以GBK解码时得到的内容一样就行了。具体方法就是把当前的字节序列先以GBK解码,再以UTF-8编码,然后写回文件系统里,就搞定了。这个命令在Linux上就是iconv -f GBK -t UTF-8(记得加管道)。
functionaverage(arr:arrayof longint):real; var i:longint; begin average:=0; for i:=0to high(arr) do average:=average+arr[i]; average:=average/length(arr) end;
请注意其中high()和length()的区别。合法调用如下:
var A:array[1..MAX]of longint;average([3]);average([1,2,3,4]);average(A);average(A[1..5]);
type TMyCompareFunc=Function(a,b:MyType):boolean; functionlargerthan(a,b:MyType):boolean; begin //... end; proceduresort(var a:arrayof MyType;l,r:longint;f:TMyCompareFunc); begin //... //Use `f(a[x],a[y])` to compare end; begin compare(arr,1,max,@largerthan); end.
type TNoArgFunc=Function():integer; var F:TNoArgFunc; N:integer; functionMyFunc():integer; begin MyFunc:=3; end; begin F:=MyFunc; //F()成为MyFunc()的别名 N:=MyFunc; //N被赋值为3
//if F=MyFunc then // writeln('You will never see this'); //这个判断将导致`类型不匹配`编译错误
type TGetSum=object a,b:longint; procedureInit(x,y:longint); functionGetSum():longint; end; procedureTGetSum.Init(x,y:longint); begin a:=x;b:=y; end; functionTGetSum.GetSum():longint; begin GetSum:=a+b; end; var sum:TGetSum; begin sum.Init(2,3); writeln(sum.GetSum()) end.
]]>
<p>各种加密方法大体可以分成两类,一类是对称加密,另一类是非对称加密。</p>
<p>凯撒密码是对称加密中的一种,他的加密方法是把A变成B,把B变成C,于是解密的时候只要把字母替换回来就行了。也就是说,任何知道加密方法的人就可以解密。</p>
<p>RSA是一种非对称加密算法,
Sync with iDevice on Linuxhttps://recursiveg.me/2012/12/sync-with-idevice-on-linux/2012-12-31T13:01:00.000Z2020-01-12T19:01:23.694ZIt’s a bit hard to connect an iDevice with Linux because Apple is not so open and we have to use iTunes to sync with our iDevice for a long time. Luckily we now have a set of tool so that we can control our device on linux. The most important two library are libimobiledevice(libiphone) and libgpod.
libimobiledevice, like it’s name, is a library who provides the interface to access the iDevice. It provides a higher level of access such as photo, bookmark, install/uninstall softwares and even sync music. And it doesn’t need jailbreak.
What I want to mention is how musics synchronized with an iDevice. Under the iTunes folder (You may never seen that before. That’s ordinary.), there’s a file called iTunesDB. That’s the file which libgpod really works with. This file contains the name of songs, singers’ names, your play lists and so on. Unfortunately, because Apple don’t want it be modified by any programs except iTunes, they add some hash info into the file. If iPod found the hash is incorrect, it refused to display the songs. There was once a project called iPodHash, but it seems to be die due to a DMCA notice. Apple engineers have changed the hash algorithm for several times and the latest version haven’t been reverse-engineering, as a result, now we can only sync with a old version of iOS.
If your iDevice is jailbreaked, you can change a key called DBVersion(Sorry, I forgot where it is.). It tells iPod which version of hash algorithm it should use so we could use a known hash on new iOS. This process depends on libimobiledevice too. It only support to sync with iOS 4 or older. That means it’s useless even if you changed DBVersion on your iOS5 device. By the way, you may will not find a iTunesDB file but a iTunesCDB instead. It’s a compressed version of iTunesDB using zlib.
I feel so sad that such a project is closed and now I can only sync with my iPod on Windows.
]]>
<p>It’s a bit hard to connect an iDevice with Linux because Apple is not so open and we have to use iTunes to sync with our iDevice for a lo
How to solve the "Connection Reset" problemhttps://recursiveg.me/2012/12/how-to-solve-the-connection-reset-problem/2012-12-31T12:50:00.000Z2020-01-12T19:01:24.174Z考虑到安全原因,这篇文章用英语写成。如果你没有足够的勇气读完它,请自觉退出。
This article is written mainly for those people in China. Be sure you are enough familiar with what you are reading and what you try to do.
As we all known, in China mainland, we cannot visit sites like YouTube Facebook Twitter. And the Google sites are out of service frequently. It’s because the Chinese government used some technical methods to prevent us from visiting them. The government has setup a system to do this. It’s called the Great Firewall of China (GFW). This system keeps look on the gateway export. And if it finds something unusual. It will stop the connection.
The system usually inject a RESET into the TCP connection. To prevent this, we can use HTTPS(The S means Secure) instead of HTTP. So the system can not inject the RESET any more. It’s easy to perform. You just need to replace the “http://“ part of a URL with “https://“. And the URL will look like this “https://www.facebook.com". Most of the sites support a HTTPS connection.
Unfortunately, this will not always works. Because the system also used another method called “DNS Redirection”. As we all known, the computers on the Internet are identified by IP address. But human can’t remember them easily. So we use some meaningful phases called “Domain”. Some computers on the Internet provide the kind of service to translate the domains to IP address which is the only form computers can recognize. They are called the “DNS Server”. DNS Redirection is that the DNS servers won’t return the correct IP address (usually were instructed to do so) so that we can’t visit the particular sites.
Luckily, we can assign an IP to a domain manually. That’s the function of a file called hosts. There’s a project called smarthosts on Google Code. It provided a set of IP address you may use. Paste them to your local hosts file and enjoy the Internet.
I will write more about the Internet censorship and how to avoid it. Check back later.
]]>
<p>考虑到安全原因,这篇文章用英语写成。如果你没有足够的勇气读完它,请自觉退出。</p>
<p>This article is written mainly for those people in China. Be sure you are enough familiar w
Hello, World!https://recursiveg.me/2012/12/helloworld/2012-12-22T12:32:00.000Z2020-01-12T19:01:24.704ZA standard “Hello World!” page
你好世界。
hello_world.pas
1 2 3 4
program Hello_World; begin writeln('Hello World!'); end.






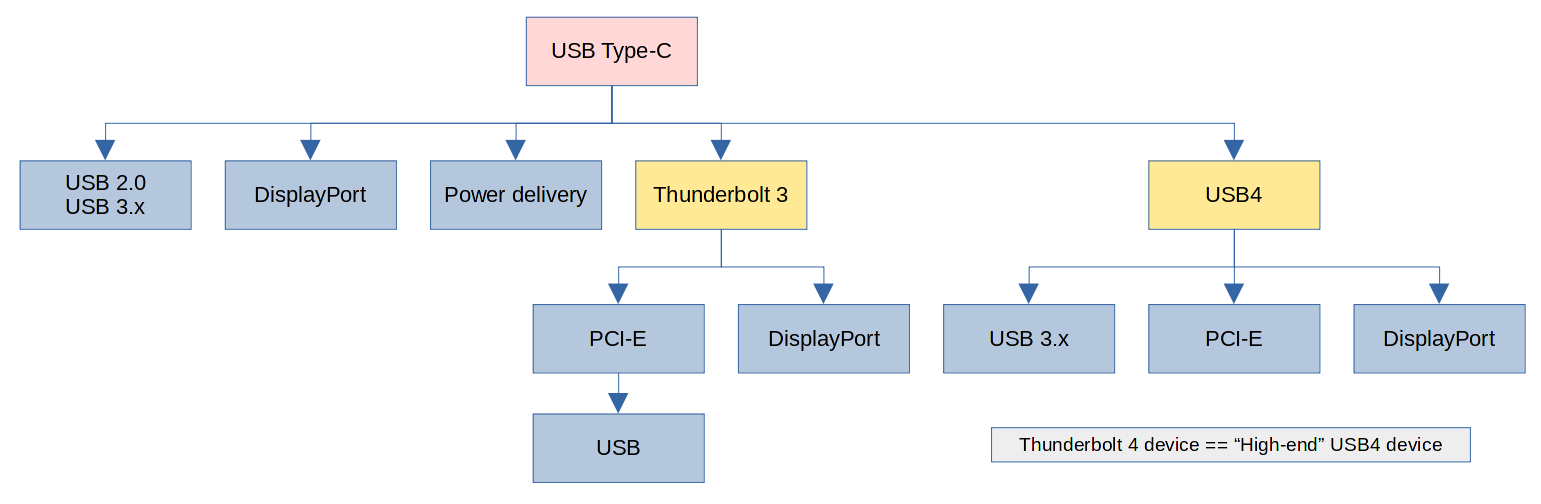
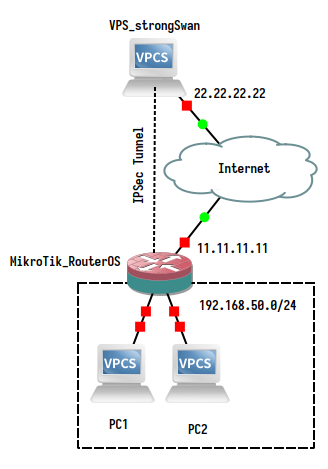
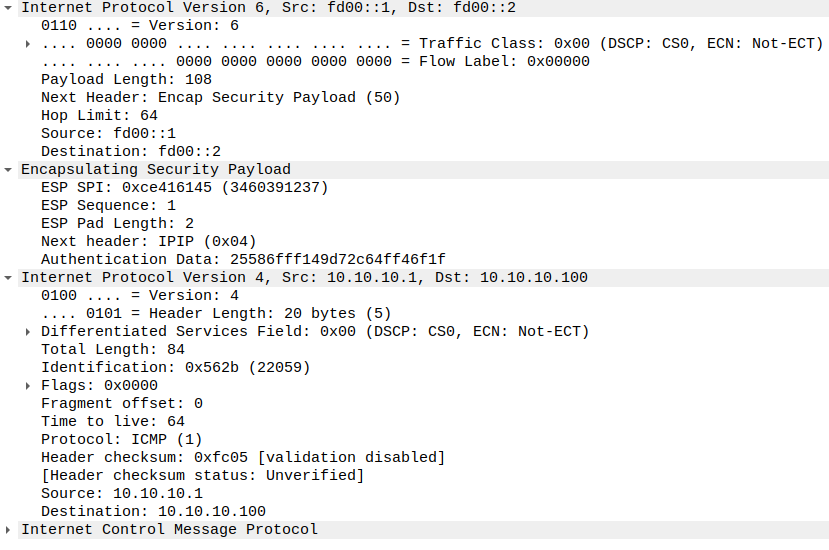
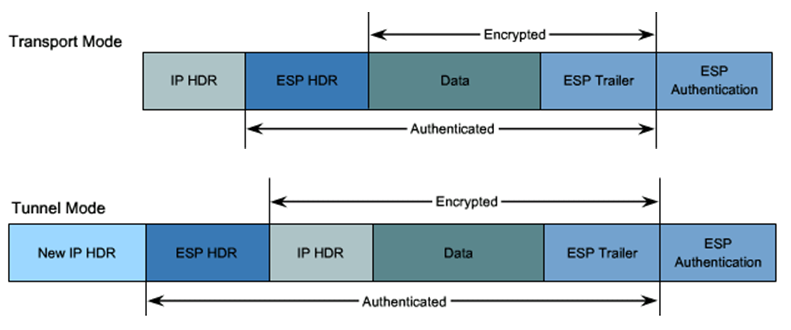 前两篇中我们使用的都是 Transport 模式,但是实际使用中,更常用的是 Tunnel 模式。Transport 模式只加密四层及以上数据,而不修改 IP 头,原始的 IP 头将会原样传输。这意味着我们只能进行点对点传输,因为只有一个 IP 头,我们无法告知对方服务器我们实际要访问的地址。Tunnel 模式则是连原始的 IP 头也一起加密,然后再在前端添加一个新的 IP 头,这样服务器在收到数据包后,可以解密并读取内部的 IP 头,再转发给实际的目标服务器。
前两篇中我们使用的都是 Transport 模式,但是实际使用中,更常用的是 Tunnel 模式。Transport 模式只加密四层及以上数据,而不修改 IP 头,原始的 IP 头将会原样传输。这意味着我们只能进行点对点传输,因为只有一个 IP 头,我们无法告知对方服务器我们实际要访问的地址。Tunnel 模式则是连原始的 IP 头也一起加密,然后再在前端添加一个新的 IP 头,这样服务器在收到数据包后,可以解密并读取内部的 IP 头,再转发给实际的目标服务器。